
-
Project Summary
-
Overview:
For the proposed project, a team of experts in Trans-Himalayan documentary and descriptive linguistics and in differential marking in these languages (Chelliah, DeLancey, Evans) propose to team up with native-speaking Boro linguists (Boro, Basumatary) and Dimasa linguist-in-training (Langthasa) and computational linguist Alexis Palmer to create IGT and a derivative grammatical sketch and word list for Dimasa. Dimasa (dis) is a Trans-Himalayan language spoken primarily in Assam state, India with about 137,000 native speakers. It is one of three closely related Bodo-Garo languages, the other two being Boro (brx) with 1.5 million speakers, and Kokborok (trp) with 970,000 speakers.
Intellectual Merit:The documentary process will be enhanced by three activities:
(1) workshops for cross-language comparison of IGT between Dimasa and Boro
(2) creating enhanced IGT by adding to the traditional 5-line annotation (transcription, morpheme breaks, morpheme gloss, word gloss, free translation) with additional annotations for semantic factors that might trigger differential marking (DM) and creating a replicable and scalable process for this using
(3) Check and improve analysis through metagrammar discussions by the community rather than non-speaker deductions based on single texts or limited corpus. The intellectual merit lies in the expertise of the team, the potential to discover related factors triggering DM in Trans-Himalayan, the testing of new methods of enhancing morphological annotation and training native-speakers in annotation and data elicitation.
Broader Impacts:
Thus far, our documentary methods have been for the outsider, the non-speaker. It is now necessary to create methods responsive to the needs of the speaker-linguist. Much of the morphosyntactic documentation for Indian languages consists of translated clauses from elicitation schedules. Yet speaker-communities desire richer documentation - documentation that preserves and provides access to cultural and linguistic heritage and reflects their understanding of grammar. There are many linguists-in-training from these communities that would benefit from the methodologies we propose so that they can create IGT and can guide analysis through their own commentaries on how grammar interacts with information and discourse structure. The wide dissemination of our proposed methodologies will potentially improve and increase documentation of Indian languages and can be adapted for native-speaker-guided language documentation and description elsewhere. -
Personnel
-
Senior Personnel
Shobhana Chelliah, PI, Distinguished Research Professor at University of North Texas
Alexis Palmer, Co-PI, Assistant Professor at University of Colorado Boulder
Scott DeLancey, Co-PI, Professor at University of Oregon
Consultants
Jonathan Evans, Associate Research Fellow at Academia Sinica
PhD, Linguistics, University of California, Berkeley, 1999
Research interests: Qiang, Dimasa, phonetics, phonology, historical linguistics
Krishna Boro, Assistant Professor at Gauhati University
Prafulla Basumatary, Post-Doctoral Scholar at Gauhati University
Research Assistants
Dhrubajit Langthasa, MA student at University of North Texas
Kristy Phillips, PhD student at University of North Texas
Benjamin Hull, MA student at University of North Texas
Merrion Dale, former MA student at University of North Texas
-
Activities
-
Reading Groups
As part of our background research, we hosted two reading groups during Summer/Fall of 2020. We met with our research team and an extended group of colleagues and students from Indiana University. Each of these meetings was heavily attended and highly productive. Our aim was first to establish a solid understanding of Tibeto-Burman grammar, then to conduct a cross-language comparison of two of the languages most relevant to our current research interests, Boro and Dimasa.
(Summer 2020) Tibeto-Burman Grammar Reading Group
(Fall 2020) Boro, Dimasa, KokBorok Reading Group
Annotation Manual
Throughout this entire process we have been creating an annotation manual for the purpose of guiding native-speaker linguist-in-training analysis of Differential Marking triggers. The ultimate goal for this project is the piloting of a reproducible methodology for the documentation and encoding of discourse-level features, which will ideally facilitate robust and timely community-led documentation of low-resource languages.
(Summer 2020) Annotation Manual Reading Group
The aim for our first reading group was to establish a solid understanding of Tibeto-Burman grammar. We spent our meeting time comparing the grammatical structures of Meithei, Lamkang, Mizo, Khumi, and Hakha Lai, among other Tibeto-Burman languages. Each week we had a different focus, ranging from clause structure, to verb inflection, to post positionals, directionals, and semantic role marking. Additionally, we had the opportunity to discuss the ongoing research of individual participants of the group, namely Patricia McDonough and her work on Thangal. You can find the syllabus linked here.
Dimasa Grammar Boot Camp
We held a five-day workshop at the University of North Texas in July to discuss aspects of Dimasa grammar and our progress with ELAN annotation. The program is here. Photographs from the event here:
Project participants Dhruv Langthasa, Ben Hull, Jonathan Evans, Shobhana Chelliah and virtually Alexis Palmer and Kristy Phillips took part in deep dives into Dimasa data. Bill Salmon, Nick Lester, Dorian Roehrs, Mary Burke - all provided great discussion and suggestions.
-
Software
-
SayMore, FLEx, and ELAN Sync-Up
The analysis of our texts will happen in FLEx and ELAN, but we will actually start in SayMore for each text. When you open SayMore, go to Project > Open/Create Project. Select “Create new, blank project.” Give your project a title.
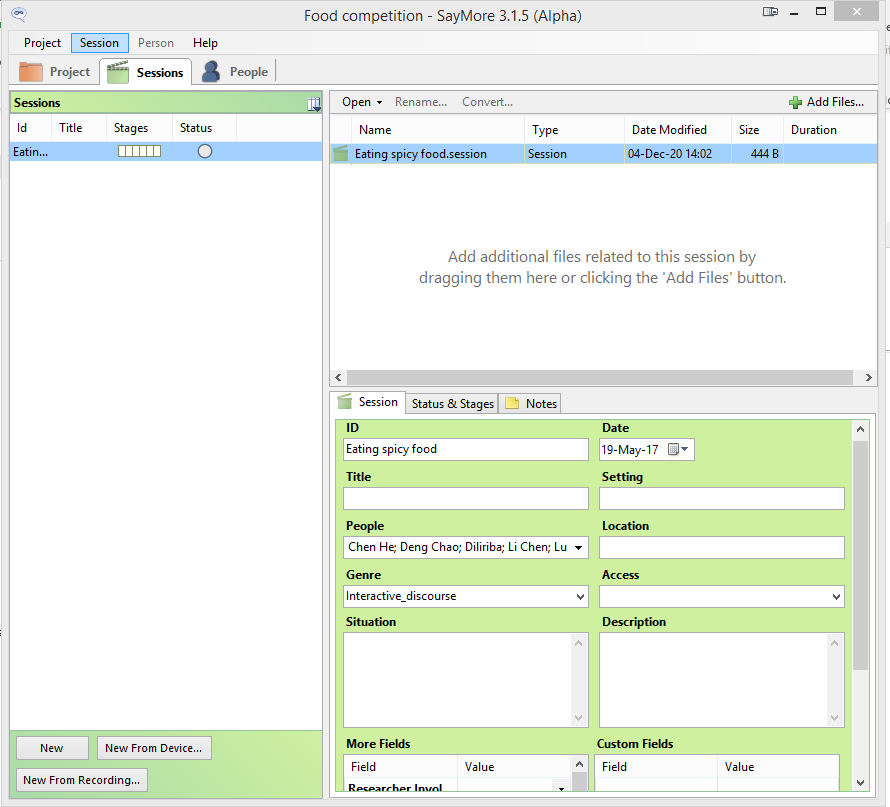
The project will open to the “About This Project” page. Fill in as much metadata as possible *. Then click on the “Sessions” tab.
Click on “New”, then fill in the metadata for the session. After this, click on “Add files” and select the media recording to be added.
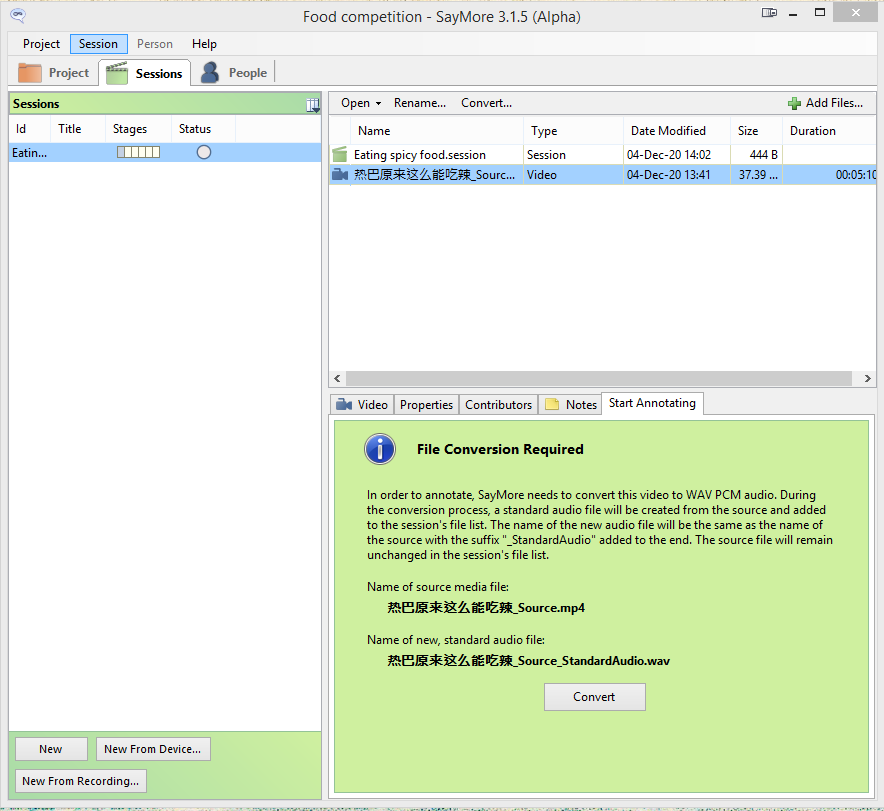
Click on “Start Annotating.” If your file was a video, you will also have to click on “Convert.”
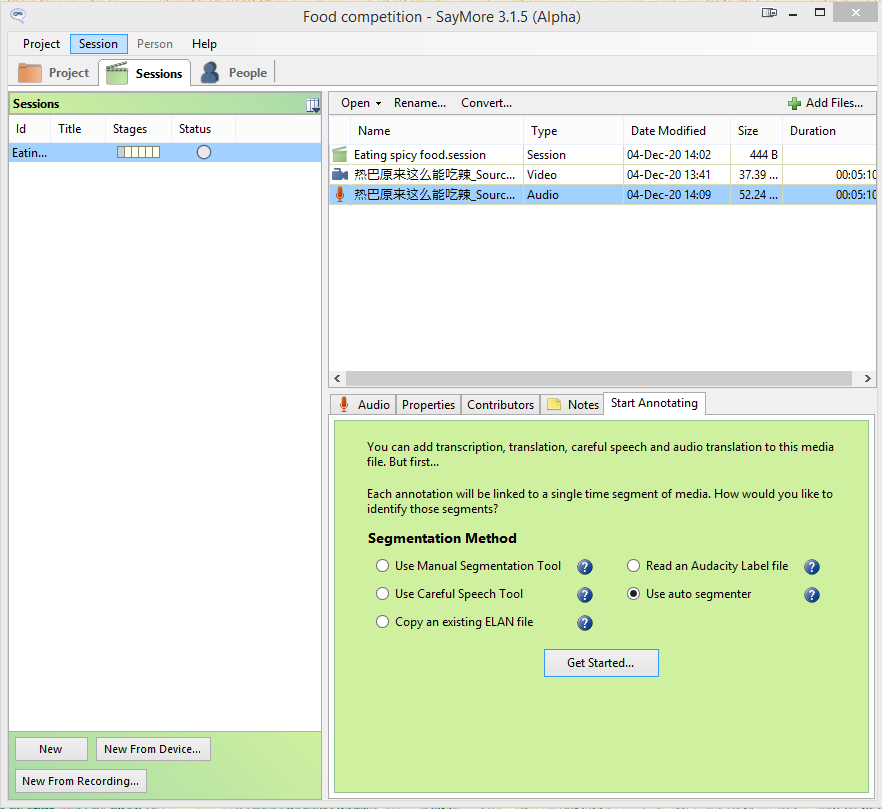
Next, you will have to choose the segmentation mode. The default is probably “Use auto segmenter.” It is easiest to begin by using the auto segmenter; you can always adjust the segments later.
After this, go ahead and click “Get started…”
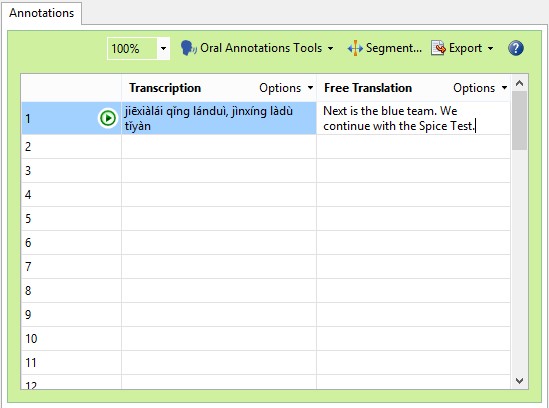
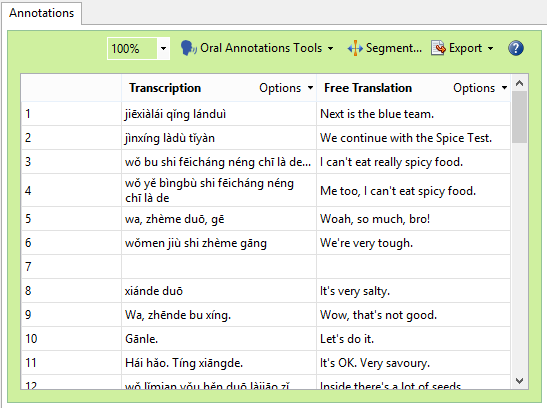
You can click on each row. The audio will automatically play. You can write both the transcription and the free translation.
If you need to make any changes, you can click the “Segment” button. Follow the instructions there to add, delete, or move segment boundaries. The segments should line up with clauses or sentences.
Make sure you have everything lined up correctly in SayMore. Remember, everything needs to be exactly the same in FLEx and ELAN, so it is easiest to get everything right while it is still in Saymore.
Once you are done, you are ready to export into FLEx and ELAN. For FLEx, click Export>FLEx Interlinear Text. You will have to select the languages used, then choose the file’s name and location. You can then import this file into the FLEx project*.
To open the project in ELAN, double-click the “Annotations” file (it should end in “.eaf”), and it will open automatically.
Make sure to save the ELAN file! (Go to File>Save as.)
XIGT
To encode semantic- and pragmatic-level information in a machine-readable format, we use Xigt (Goodman et al., 2015) to extend the Interlinear Glossed Text format. We add additional tiers to the standard lexical, syntactic, and morphemic information outlined by the Leipzig Glossing Rules (Comrie et al., 2008) for the phenomena that we are documenting.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}